Publications
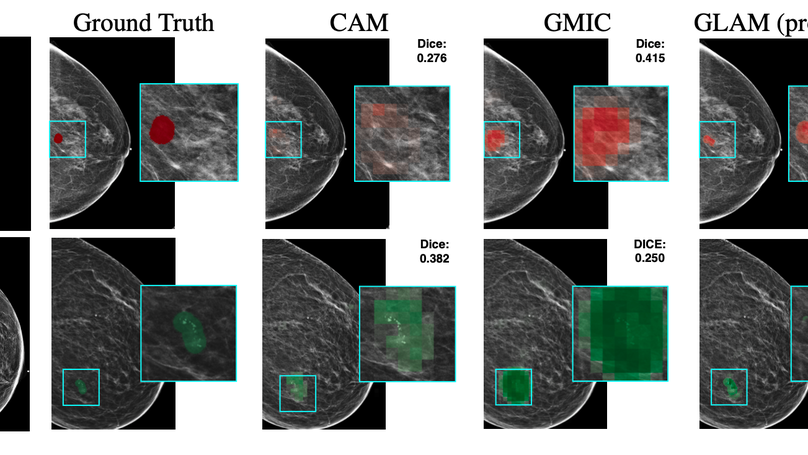
In the last few years, deep learning classifiers have shown promising results in image-based medical diagnosis. However, interpreting the outputs of these models remains a challenge. In cancer diagnosis, interpretability can be achieved by localizing the region of the input image responsible for the output, i.e. the location of a lesion. Alternatively, segmentation or detection models can be trained with pixel-wise annotations indicating the locations of malignant lesions. Unfortunately, acquiring such labels is labor-intensive and requires medical expertise. To overcome this difficulty, weakly-supervised localization can be utilized. These methods allow neural network classifiers to output saliency maps highlighting the regions of the input most relevant to the classification task (e.g. malignant lesions in mammograms) using only image-level labels (e.g. whether the patient has cancer or not) during training. When applied to high-resolution images, existing methods produce low-resolution saliency maps. This is problematic in applications in which suspicious lesions are small in relation to the image size. In this work, we introduce a novel neural network architecture to perform weakly-supervised segmentation of high-resolution images. The proposed model selects regions of interest via coarse-level localization, and then performs fine-grained segmentation of those regions. We apply this model to breast cancer diagnosis with screening mammography, and validate it on a large clinically-realistic dataset. Measured by Dice similarity score, our approach outperforms existing methods by a large margin in terms of localization performance of benign and malignant lesions, relatively improving the performance by 39.6% and 20.0%, respectively. Code and the weights of some of the models are available at https://github.com/nyukat/GLAM