Abstract
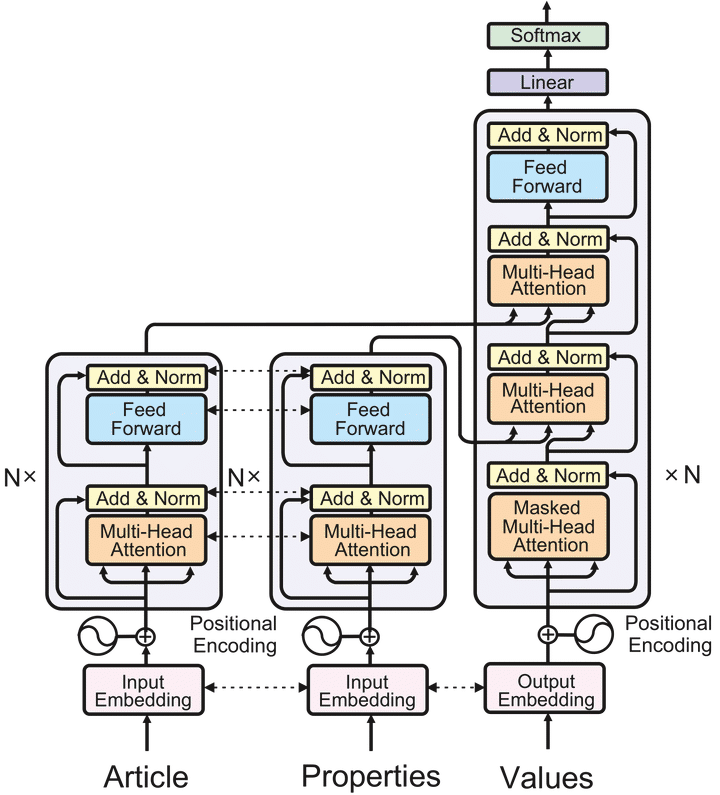
This paper investigates various Transformer architectures on the WikiReading Information Extraction and Machine Reading Comprehension dataset. The proposed dual-source model outperforms the current state-of-the-art by a large margin. Next, we introduce WikiReading Recycled - a newly developed public dataset, and the task of multiple-property extraction. It uses the same data as WikiReading but does not inherit its predecessor’s identified disadvantages. In addition, we provide a human-annotated test set with diagnostic subsets for a detailed analysis of model performance.
Jakub Chłędowski
Deep Learning Researcher, PhD Student
PhD student interested in applying deep learning in practice. My current research revolves around the topic of breast cancer detection. Supervised by prof. Krzysztof Geras and dr. Stanisław Jastrzębski.